
Cara Mengatasi Data Berdistribusi Tidak Normal
Ketika kita hendak melakukan analisis statistik parametrik, seperti melakukan uji korelasi product moment, salah satu asumsi yang harus dipenuhi adalah distribusi data kita normal. Oleh karena itu sebelum melakukan analisis statistik parametrik, terlebih dahulu kita harus melihat apakah data kita terdistribusi normal atau tidak. Bagaimana cara untuk melihat data kita normal atau tidak? Berikut akan diberikan contoh penelitian fiktif tentang “Hubungan antara Pelayanan Istri dengan Kepuasan Suami”. Data fiktif dapat didownload disini
Uji Normalitas di SPSS
Data yang akan kita gunakan adalah data kepuasan.sav. Sebelum menguji hipotesis kita yakni “ada hubungan antara pelayanan istri dengan kepuasan suami”, maka kita uji terlebih dahulu normalitas data kepuasan dan pelayanan kita. Ada berbagai cara untuk menguji normalitas di SPSS, seperti dengan melihat histogram dan nilai skewness dan kurtosis serta dengan uji kolmogorov-smirnov. Contoh kali ini kita akan menggunakan uji kolmogorov-smirnov. Uji normalitas dengan kolmogorov-smirnov dilakukan dengan membandingkan distribusi empirik data kita dengan distribusi normal yang diharapkan. Karena merupakan uj beda, maka nilai p yang diharapkan adalah yang tidak signifikan, yakni p>0,05. Hal ini menunjukkan bahwa tidak ada perbedaan antara kedua distribusi itu, yang berarti distribusi data empirik kita adalah normal. Untuk menguji normalitas di SPSS dapat dilakukan melalui menu analyze – nonparametric test – legacy dialogs – sample K-S.

Jika sudah, pindahkan kedua variabel pelayanan dan kepuasan ke kotak sebelah kanan, kemudian tekan OK. Berikut adalah output dari analisis kita.

Dari output tersebut dapat kita lihat, variabel pelayanan memiliki nilai kolmogorov-smirnov Z sebesar 1,277 dan p=0,077 (p>0,05), dengan demikian tidak ada perbedaan antara distribusi empirik data kita dengan distribusi normal ideal, oleh karena itu distribusi data variabel pelayanan normal. Sedangkan pada variabelkepuasan memiliki nilai kolmogorov-smirnov Z sebesar 1,447 dan p=0,030 (p<0,05), dengan demikian ada perbedaan antara distribusi empirik data kita dengan distribusi normal ideal, oleh karena itu distribusi data variabel kepuasan tidak normal. Lalu bagaimana kita memperlakukan data yang tidak normal kita? Ada beberapa cara yang bisa dilakukan untuk mengatasi data yang tidak normal tersebut.
Membuang outliers
Salah satu alasan mengapa data kita tidak normal adalah adanya outliers. Outliers adalah data yang memiliki skor ekstrem, baik ekstrem tinggi maupun ekstrem rendah. Adanya outliers dapat membuat distribusi skor condong ke kiri atau ke kanan. Beberapa ahli menilai data outliers ini lebih baik kita buang, karena ada kemungkinan subjek mengerjakan dengan asal-asalan, selain itu adanya data outliers juga mengacaukan pengujian statistik. Namun beberapa ahli tetap mendukung bahwa data outliers tetap harus dimasukkan dalam analisis karena memang fakta di lapangan adalah demikian. Dalam kasus ini, kita akan membuang outliers yang dapat mengacaukan data kita, sehingga diperoleh distribusi yang normal.
Untuk melihat data outliers, kita dapat melakukannya di menu analyze – descriptive statistics – explore.Kemudian kita masukan variabel yang dinyatakan tidak normal, yakni variabel kepuasan ke kotak dependent list, lalu klik menu statistics dan centang bagian outliers. Jika sudah klik continue dan OK.

Untuk melihat data mana saja yang terindikasi sebagai outliers, kita dapat langsung menuju bagian boxplot pada output. Hasil output boxplot data kita dapat dilihat pada gambar di bawah.

Gambar tersebut mengindikasikan data-data mana saja yang terindikasi merupakan data ekstrem atau outliers. Jika data berada di atas kotak, menunjukkan data ekstrem tinggi, sedangkan jika berada di bawah kotak menunjukkan data ekstrem rendah. Semakin jauh dari kotak, semakin ekstrem data tersebut. Dari output di atas kita dapat melihat bahwa subjek nomer 1, 2, 3, 4, 5 terindikasi sebagai outliers. Subjek nomer 1 merupakan subjek yang paling ekstrem nilainya.
Untuk memilih data mana saja yang ingin kita buang, lebih baik kita melakukannya secara bertahap, mulai dari data yang paling ekstrem. Jika dilihat dari output tersebut, data nomer 1 dan 2 adalah data yang paling ekstrem, oleh karena itu kita buang data dari 2 subjek tersebut terlebih dahulu. Untuk menghapus, jangan lupa, kita menghapus dari subjek yang bawah terlebih dahulu, agar nomer subjek tidak bergeser nantinya. Untuk menghapus data subjek, klik kanan pada nomer subjek, lalu pilih clear.

Jika kedua outliers tersebut telah kita hapus, maka kita uji kembali normalitas data kita dengan kolmogorov-smirnov. Hasil uji kolmogorov-smirnov yang baru ditunjukkan gambar di bawah.

Hasil uji kolmogov-smirnov yang baru pada variabel kepuasan ternyata menghasilkan nilai kolmogorov-smirnov Z sebesar 1,265 dan p=0,81 (p>0,05). Dengan demikian distribusi data variabel kepuasan normal. Begitu juga pada variabel pelayanan yang memiliki p>0,05, sehingga variabel pelayanan juga terdistribusi normal. Dengan demikian masalah ketidaknormalan data kita sudah teratasi.
Transformasi Data
Jika beberapa ahli tidak setuju dengan cara menghapus data-data ekstrem, cara lain yang bisa ditempuh adalah dengan transformasi data. Transformasi data dilakukan dengan mengubah data kita dengan formula tertentu tergantung dari bentuk grafik kita. Sebelum melakukan transformasi data, kita harus tahu terlebih dahulu bagaimana bentuk grafik kita. Cara melihat grafik data kita adalah dengan cara analyze – descriptive statistics – frequencies. Lalu masukkan variabel kepuasan dan pilih menu chart, pilihhistogram dan centang show normal curve on histogram. Jika sudah tekan continue dan OK, maka akan diperoleh output seperti berikut.

Grafik tersebut menggambarkan kurve kita condong ke kanan. Beberapa kemungkinan grafik yang akan muncul adalah sebagai berikut.
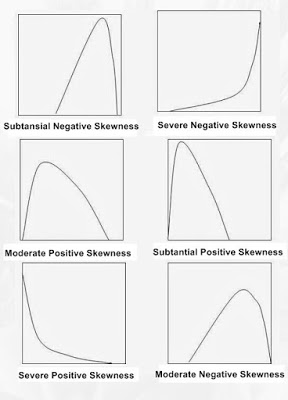
Sumber gambar: http://i-codee.blogspot.co.id
Panduan transformasi data berdasarkan bentuk grafik dapat dilihat di tabel di bawah.
|
Bentuk Grafik Histogram |
Bentuk Transformasi Data |
|
Moderate positive skewness |
SQRT(x) |
|
Substansial positive skewness |
LG10(x) |
|
Severe positive skewness |
1/x |
|
Moderate negative skewness |
SQRT(k-x) |
|
Substansial negative skewness |
LG10(k-x) |
|
Severe negative skewness |
1/(k-x) |
k = nilai tertinggi dari data mentah x
Jika kita kembali ke data kita dan melihat grafik histogram kita, maka bentuk grafik kita adalah moderate negative skewness, sehingga transformasi data yang kita pakai adalah SQRT(k-x). K adalah nilai tertinggi dari data mentah variabel kepuasan, yakni 25. Untuk mentransformasi data, kita dapat klik transform – compute variable. Pada kotak target variable, kita ketik nama variabel baru kita, misal trans_kepuasan,kemudian pada pada numeric expression, masukkan formula kita yakni SQRT(25-kepuasan), lalu klik OK. Kembali lagi ke data kita, maka kita sudah memiliki variabel baru bernama trans_kepuasan yang tidak lain adalah transformasi data dari variabel kepuasan.

Untuk melihat apakah transformasi data kita berhasil atau tidak, kita uji kembali normalitas data kita dengan kolmogorov smirnov.

Dari hasil uji kolmogorov-smirnov, diperoleh p>0,05, sehingga dapat dikatakan bahwa variabel transformasi kepuasan ini terdistribusi secara normal.
Catatan mengenai transformasi data:
- Transformasi data tidak hanya dapat digunakan untuk mengatasi ketidaknormalan data, tapi juga dapat digunakan untuk mengatasi pelanggaran asumsi lainnya, seperti lineraritas dan homogentitas varians pada uji beda. Meskipun umum digunakan, namun penggunaan transformasi data sendiri juga tidak lepas dari pro dan kontra. Beberapa diskusi terkait dapat dilihat di sini
- Jika transformasi data dilakukan, maka data yang ditampilkan dalam laporan kita tetaplah data asli. Namun data yang digunakan untuk uji statistik parametrik menggunakan data transformasi.
- Jika uji statistik dilakukan untuk mengkorelasikan dua atau lebih variabel, maka setiap variabel juga harus ditransformasikan dalam bentuk yang sama. Artinya, dalam contoh di atas, variabel pelayanan juga harus ditransformasi ke bentuk SQRT(k-pelayanan).
Mengubah Analisis ke Non-Parametrik
Cara terakhir jika dengan menghapus outliers dan mentransformasi data kita belum berhasil adalah dengan mengubah teknik analisis kita ke analisis non-parametrik. Analisis non-parametrik tidak memerlukan asumsi normalitas seperti yang diperlukan pada analisis parametrik. Meskipun demikian, daya generalisasi analisis non-parametrik ini tentu lebih lemah jika dibandingkan dengan analisis parametrik. Beberapa teknik analisis pengganti analisis parametrik disajikan dalam tabel di bawah ini.
|
Analisis Parametrik |
Analisis Non Parametrik |
Fungsi |
|
Paired sample t-test |
Uji tanda |
Meneliti perbedaan dalam suatu kelompok |
|
Independent sample t-test |
Uji Mann-Whitney U; Uji Wilcoxon jumlah peringkat |
Membandingkan dua sample bebas |
|
Anava satu jalur |
Anava dengan menggunakan peringkat Kruskal-Wallis |
Membandingkan tiga kelompok atau lebih |
|
Anava dua jalur |
Anava dua jalur Friedman |
Membandingkan tiga kelompok atau lebih dengan menggunakan dua faktor yang berbeda |
|
Korelasi Pearson |
Korelasi peringkat Spearman |
Mengetahui hubungan korelasi linier antara dua perubah |
Sumber : https://www.semestapsikometrika.com

terima kasih, pak. sangat membantu dan mudah dipahami 🙂
SukaSuka
syukurlah…jangan lupa sertakan di daftar pustaka anda agar bisa jadi referensi yang bermanfaat untuk orang banyak
SukaSuka